
Як прокачати сайт і покращити вашу видимість у Google.
Про дані недавнього дослідження Semrush, 59% користувачів переглядають тільки перше посилання, запропоноване пошуковою системою. А перші 3 результати видачі одержують 75% всіх кліків. Якщо ви раділи, довівши свій сайт до другої сторінки Google, даремно туди доходять всього 0,44% користувачів.
Як потрапити до золотих рядків хіт-параду Google без реклами та додаткових вкладень? Або хоча б виправити критично важливі помилки, через які роботи додали ваш ресурс до негласного чорного списку і ранжують вас гірше? Розбираємось разом із Ксенією Крутоголовою, SEO-фахівцем в агентстві digital-маркетингу GoWeb.
Як провести технічну оптимізацію сайту
Технічна оптимізація сайту – це всі дії, які допомагають виправити технічні баги та покращити розуміння сайту пошуковими роботами. Чим вище вони оцінюють якість вашого ресурсу, тим частіше він показується у видачі. Це найшвидший спосіб на пару пунктів підняти індексацію сайту в пошуковій системі.
До основних параметрів оптимізації сайту належать:
1. Robots.txt
Robots.txt — це файл, в якому вказані «вступні» для пошукового робота: які сторінки дозволено досліджувати, а де сканування заборонено. І хоча всі дані з цього документа можуть бути тільки рекомендацією (заборонити пошуковику сканувати сторінки вашого сайту майже нереально), над його якістю все ж таки варто попрацювати.
Насамперед почніть з перевірки коректності файлу. SEO-фахівці виділяють кілька основних вимог до Robots.txt, щоб він добре сприймався пошуковим ботом:
- розмір не перевищує 500 кб
- файл у форматі txt під назвою robots — robots.txt
- він розміщений в корені сайту
- доступний для роботів (200 код відповіді сервера)
Щоб усе працювало коректно, у файлі вкажіть основні директиви команди для пошукового робота:
User-agent — вказується робот, для якого діють перелічені в robots.txt правила.
Disallow – забороняє індексування/сканування розділів чи окремих сторінок сайту.
Allow — дозволяє індексувати/сканувати розділи або окремі сторінки сайту.
Sitemap — Вказує шлях до файлу Sitemap, який розміщений на сайті.
Знайти robots.txt на вашому сайті можна, ввівши назву файлу в пошуковий рядок відразу після домену, наприклад site.com/robots.txt
Приклад файлу robots.txt https://goweb.ua/robots.txt:
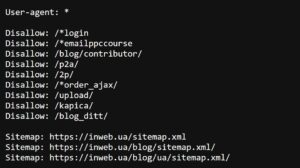
2. Мапа сайту
Файл sitemap.xml – це умовна карта, на якій зібрані всі основні сторінки сайту. Йдеться про посилання на сторінки, які пошуковий робот скануватиме і потім надсилатиме у пошукову видачу. Це обов’язковий файл для кожного великого проекту.
Основні вимоги до файлу картки сайту:
- містить лише актуальні URL-адреси
- до переліку документів не входять неканонічні сторінки — з різними URL-адресами, але з однаковим або дуже схожим змістом
- коректно вказано протокол з’єднання (наприклад, https)
- код відповіді всіх документів 200
- відсутні сторінки, які закриті від сканування та індексації (в robots.txt або в інший спосіб)
Порада: постарайтеся реалізувати карту сайту так, щоб вона оновлювалася автоматично за допомогою CMS.
3. Редиректи
Редиректи — це команди, які вказують пошуковому роботу шлях, якщо сторінку переміщено. Йдеться і про 301 redirect — постійний перенапрямок, який майже повністю передає вагу посилання, і про 302 — який повідомляє роботу, що сторінка тимчасово переїхала.
Буває, що ланцюжок редиректів не має сенсу чи може зациклюватися, створюючи нескінченне перенаправлення. Тоді неактуальних редиректів варто позбутися.
Перевірити редиректи на сайті можна за допомогою спеціалізованого софту – наприклад, Screaming Frog SEO Spider або Netpeak Spider.
4. 404 Not found
Помилка 404 — сторінка не знайдена або бита посилання — веде відвідувача на неіснуючу сторінку. Важливо періодично перевіряти, чи є на сайті такі сторінки та посилання. Коли помилок 404 дуже багато, пошуковий алгоритм сприймає ресурс як неякісний і рідше показує його у видачі.
Просканувати сайт та побачити наявність битих посилань можна за допомогою програми Screaming Frog SEO Spider або Netpeak Spider.
5. Дублікати
Дублікати — це сторінки, які мають різні посилання, але ідентичний або частково співпадаючий контент. Пошукові роботи сприймають сайти з великою кількістю дублів як неякісні, що погіршує їх індексацію.
- Через файл robots.txt, використовуючи команду disallow. Але пам’ятайте, що всі інструкції у файлі robots.txt для пошукового робота мають лише рекомендаційний характер.
- Переадресація з однієї сторінки на іншу за допомогою постійного редагування (301). Це дозволить передати основній сторінці посилальну вагу дубля.
- Атрибут rel=»canonical». Працює тільки для повних дублів, тобто ідентичних сторінок. Для цього потрібно в HTML-коді сторінки помістити атрибут rel=»canonical» між тегами <head>…</head>.
- Метатег <meta name=»robots» content=»noindex, follow>. Це допоможе закрити дубль від пошукового робота. Розмістіть метатег на дублюючих сторінках у блоці <head>.